What’s a VLM? Vision Language Models are a rapidly emerging class of multimodal AI models that’s becoming much more important in the automotive world for the ADAS sector. VLMs are built from a combination of […]
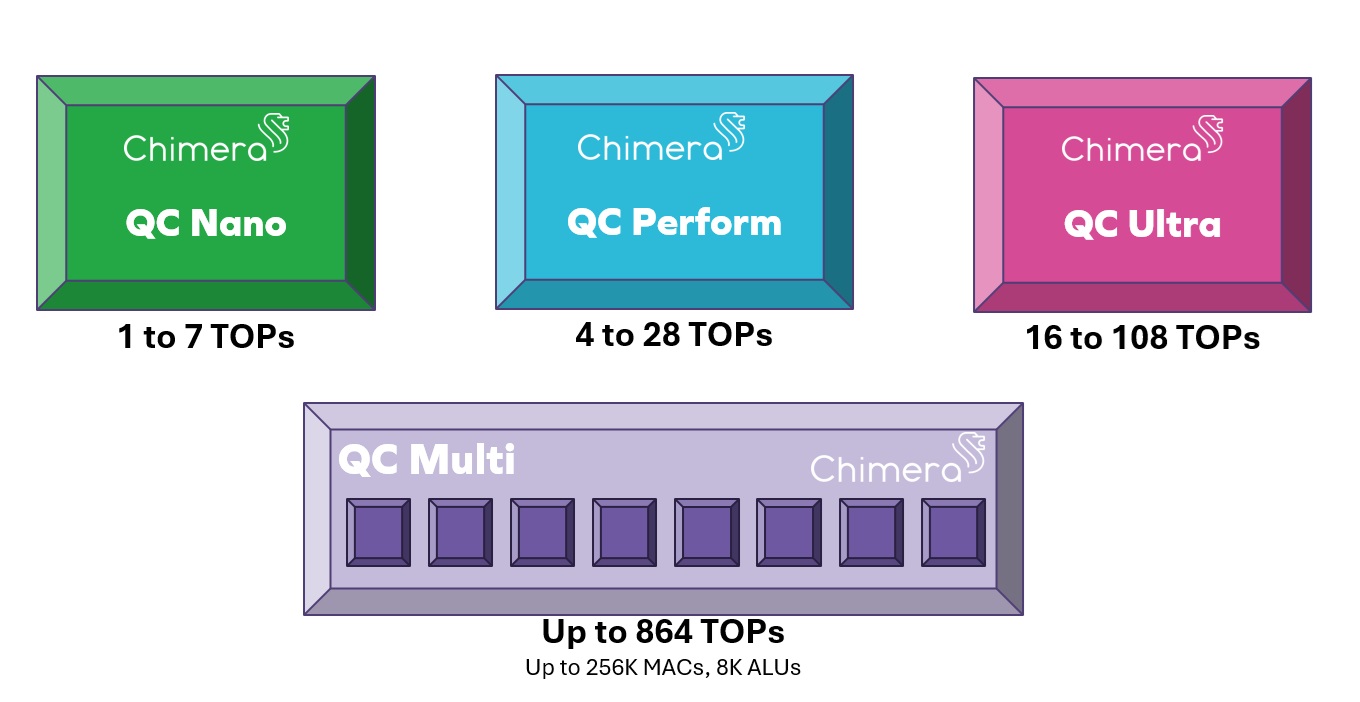
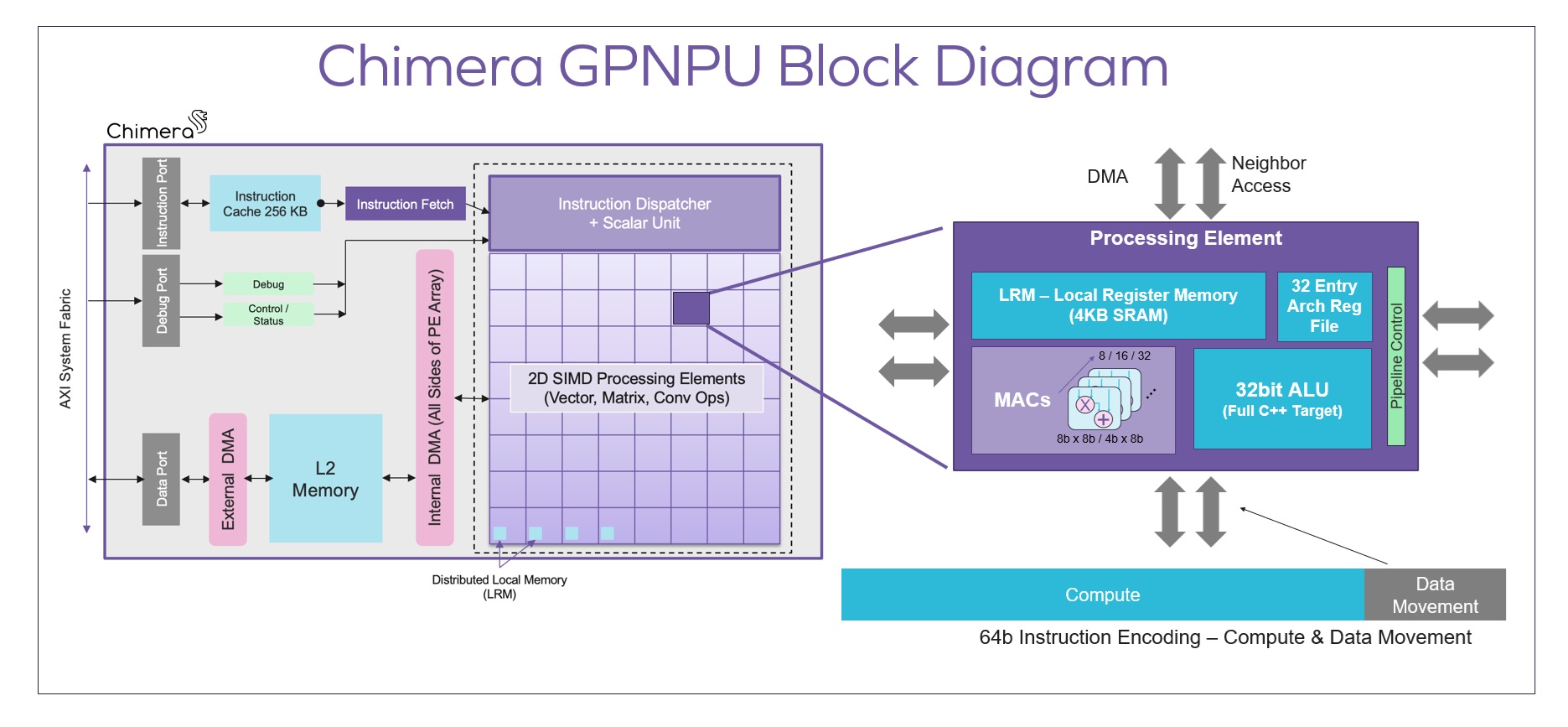
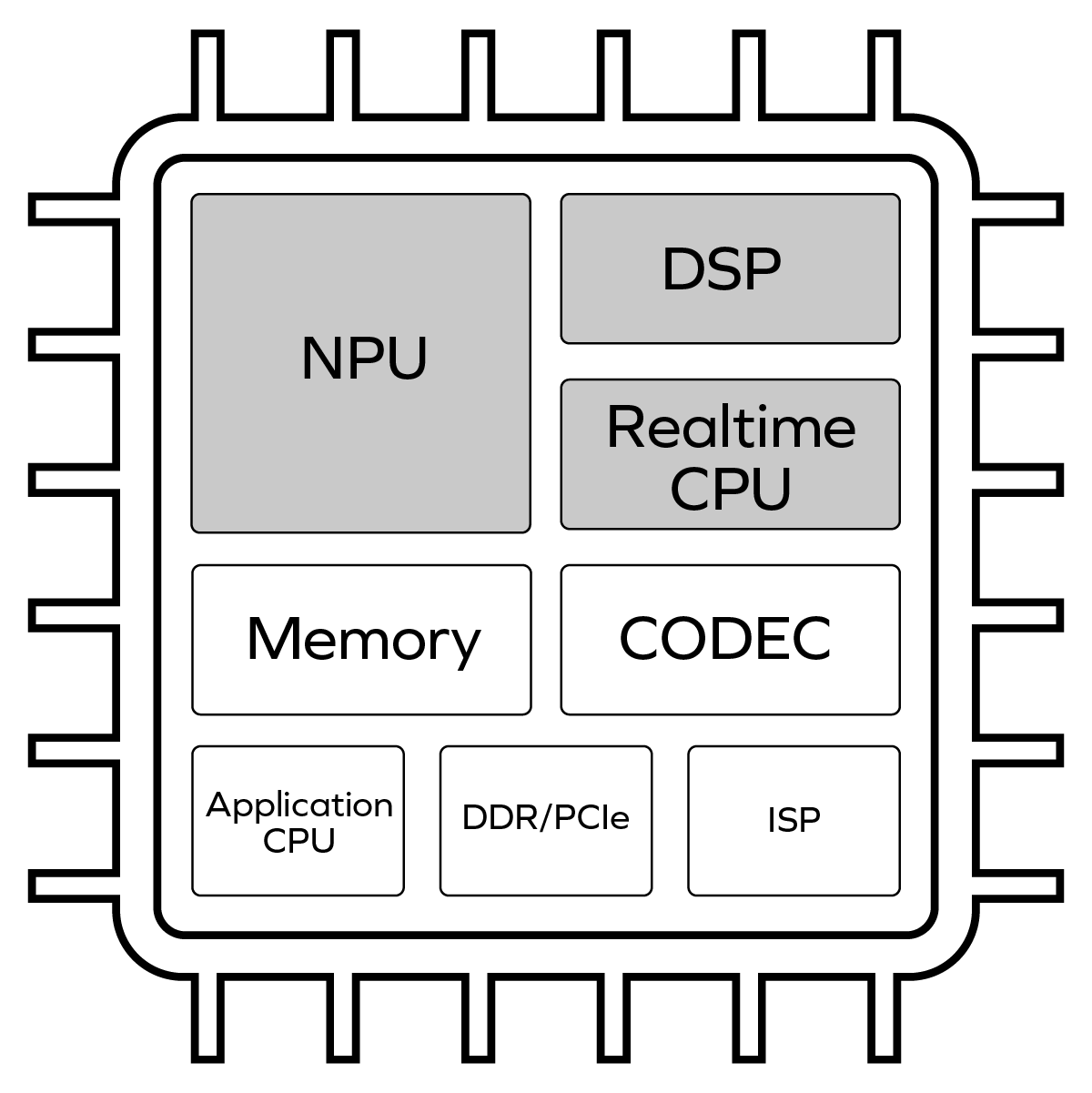
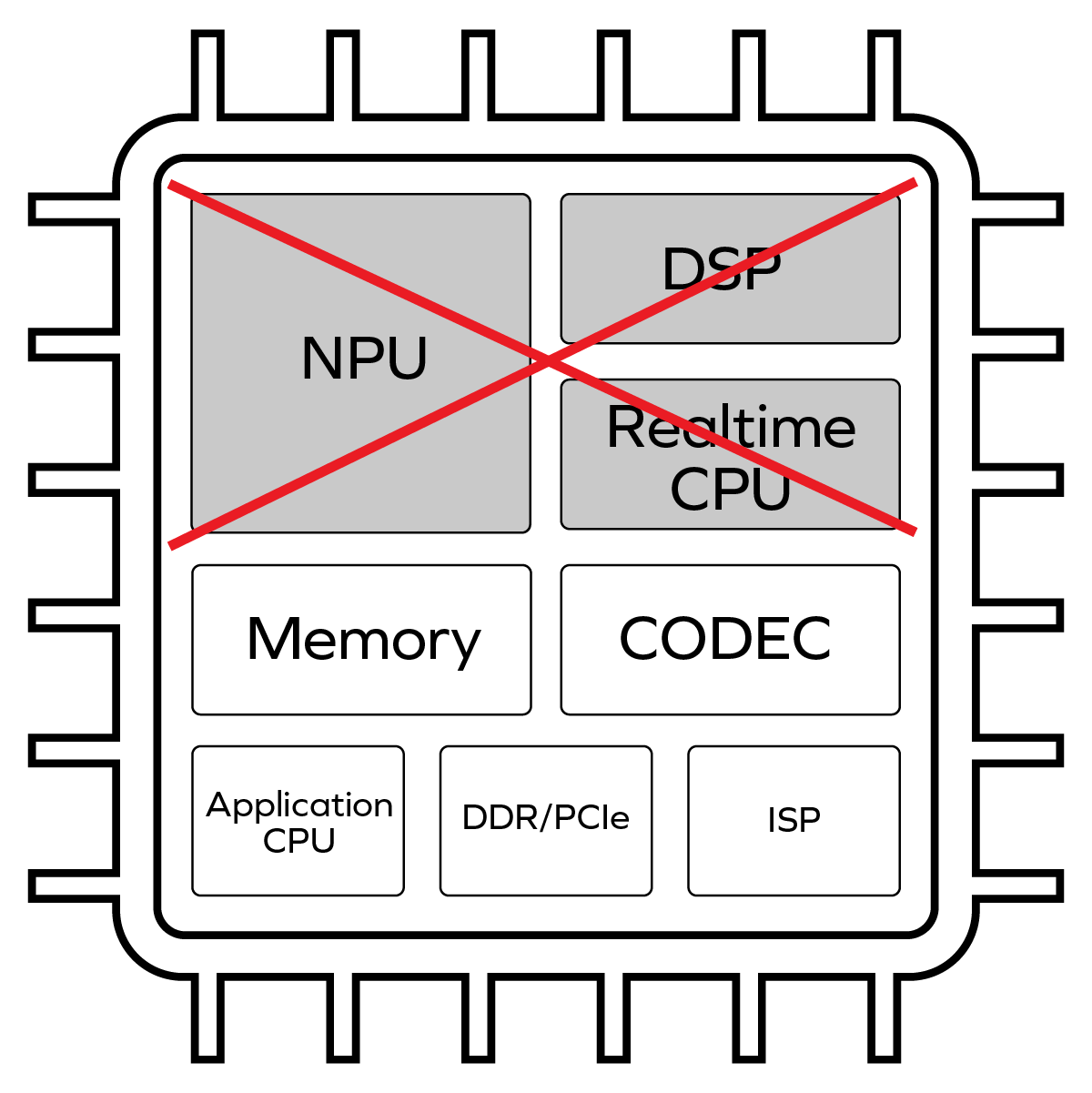
What’s a VLM? Vision Language Models are a rapidly emerging class of multimodal AI models that’s becoming much more important in the automotive world for the ADAS sector. VLMs are built from a combination of […]
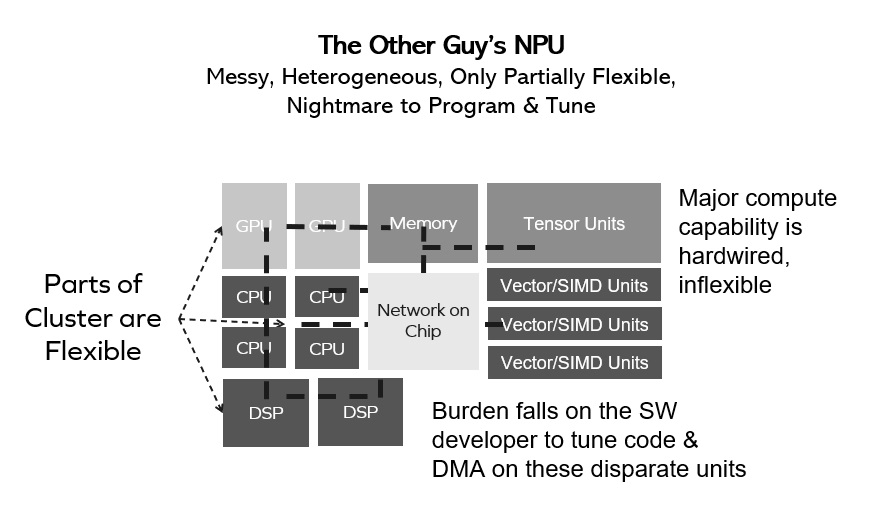
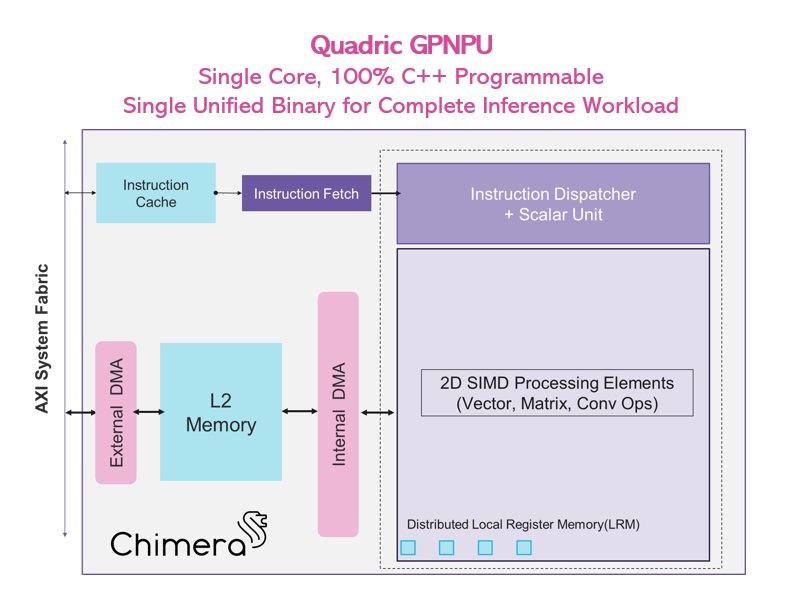
A common approach in the industry to building an on-device machine learning inference accelerator has relied on the simple idea of building an array of high-performance multiply-accumulate circuits – a MAC accelerator. This accelerator was […]
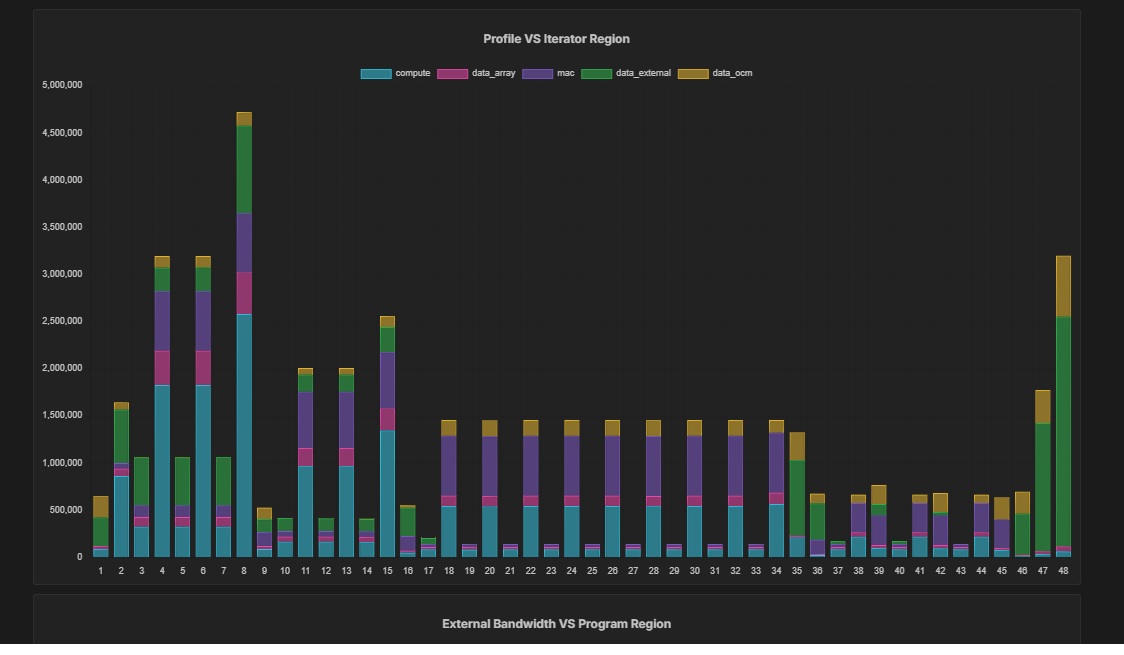
If you are comparing alternatives for an NPU selection, give special attention to clearly identifying how the NPU/GPNPU will be used in your target system, and make sure the NPU/GPNPU vendor is reporting the benchmarks […]
What’s a VLM? Vision Language Models are a rapidly emerging class of multimodal AI models that’s becoming much more important in the automotive world for the ADAS sector. VLMs are built from a combination of […]
A common approach in the industry to building an on-device machine learning inference accelerator has relied on the simple idea of building an array of high-performance multiply-accumulate circuits – a MAC accelerator. This accelerator was […]
© Copyright 2024 Quadric All Rights Reserved Privacy Policy